P2P (Peer-to-Peer) Network
Motivation
The goal of a P2P network is to offload the burden on the service provider by transfering computational, storage bandwidth resource responsibilities to the clients. It is a service architecture used to provide highly scalable & cost efficient services.
Application
A P2P network can be used for:
- Content Distribution: Napster, BitTorrent
- Internet Telephony: Skype
- Video Streaming: WebRTC
- Computation: Bitcoin
Architecture
Centralized Lookup Service
If I have some content that I want to share, how do I let everybody else on the network know that it exists? Or if I want to search content on the network, how do I know who has it?
A centralized lookup service is a directory that keeps tracks of who has what content and how it can be contacted. In the example below:
- Machine
m1is looking for contentE, but it doesn’t know which machine on the network has it. m1contacts the centralized lookup service, and is informed that machinem5has the content.m1then connects withm5directly using the its IP & port as provided by the centralized lookup service to get contentE.

Image from UC Berkeley, CS 162, Fall 2011
Pros:
- Easy to implement & deploy sophisticated features on top of a single service
Cons:
- Service needs to scale to handle growing nodes participating on the network
- Single point of failure & single source of legal vulnerability
Gnutella
One way to solve the single point of failure problem with centralized lookup service is to de-centralize the lookup. But now having removed the lookup service, how would I know where to get content?
When I join the network as a node, I will pick randomly from a list of pre-defined peers (typically hardcoded in the application) and join their network. These peers & their immediate neighbors now become my neighbors. I can then send my requests to my neighbors & have them forward my request downstream. In the example below:
- Machine
m1is looking for contentE, but it doesn’t know which machine on the network has it. m1sends a quest to its neighborsm2&m3.- Neither
m2orm3have the content, so they forward the request to their neighborsm4,m5andm6. m5happens to have the content, so it contactsm1to exchange the content.
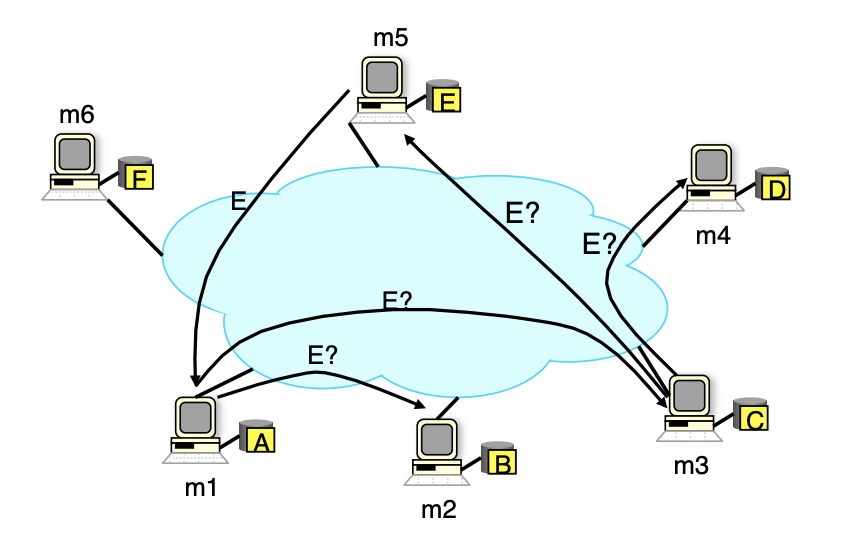
Image from UC Berkeley, CS 162, Fall 2011
Note:
A request contains the requesting node’s IP & Time-To-Live value - if a request’s Time-To-Live reaches 0 before the content is found, the request is dropped altogether. This limits the possibility of requests flooding the network.
Pros:
- Completely decentralized
Cons:
- Requests can potentially flood the network as nodes grow, ending up with more query traffic than content traffic
- Horizon effect introduced by Time-To-Live; common resources are easy to find while rare resources can seldom be reached
KaZaa
In addition to some of the problems seen in the previous topologies, there are other challenges yet to be addressed in P2P networks:
- Dynamicity: Each node on the network can be online & offline at any time. Requests might not make it too far downstream before it is dropped.
- Heterogeneity: Each node on the network has different capacity (bandwidth, computation power). Requests going through a deprived node could lead to a performance bottleneck.
To solve these problems we identify the nodes that are consistently online with good capacity, and designate them as ultra-peers. We can assign these ultra-peers as the first point of contact to all other leaf nodes. Utlra-peers themselves are also connected to fellow ultra-peers, forming a two-level topology. A request going through an ultra-peer is advertised to all leaf nodes & other ultra-peers.

Image from UC Berkeley, CS 162, Fall 2011